
Transformer: The Architecture Behind Modern Large Language Models
- VenusMoon

- Nov 11, 2025
- 5 min read
This is the first post in a 4-part series on Transformers.
Transformer: Post 1 of 4 | Post 2 coming up soon!
When we think of architecture, beautiful images often come to mind. For example:

Building/Monument | Architecture Style |
Taj Mahal, India | Mughal Architecture |
Rashtrapati Bhavan, India | Indo-Saracenic & Edwardian Baroque |
Eiffel Tower, France | Industrial Architecture |
In a similar way, the architecture of today’s Large Language Models (LLMs) is a deep neural network called the Transformer. Introduced in 2017 by researchers at Google, this architecture has become the foundation for virtually every state-of-the-art language model, from BERT and T5 to GPT-5 and Claude.
What Makes Up a Transformer?
At its heart, a Transformer consists of five essential components:
Encoder
Self-Attention Mechanism
Positional Encoding
Decoder
Feedforward Network
Yes, that may sound a bit too technical—think of them as the “structural beams” and “design patterns” that make language understanding possible. We’ll go through these components one by one and learn how they work together to build a Transformer.
Finally, it’s worth noting that GPT (Generative Pre-trained Transformer)—the model family behind ChatGPT—is itself based on the Transformer architecture.
Quick Links
#1: Language Modelling
Before we see tokenisation and attention, it’s worth understanding the central idea behind all language models — language modelling itself.
At its core, a language model learns to estimate the probability P of the next word (or token) in a sequence, given all the words (or tokens) that came before it.
In simple terms:
P(next word∣previous words)This means the model looks at a piece of text and tries to predict what’s most likely to come next. Over time — and with enormous amounts of training data — the model builds a probability distribution over words and phrases.
That’s how it learns patterns like:
"Humpty Dumpty sat on a … wall"
or
“The sky is … blue”
By sampling from these probabilities, the model can generate new, coherent text.
Because the model produces words one after another based on the context, such models are called generative models. They don’t just classify or analyse — they create.
In essence, Language modelling is the art of teaching a computer to predict the next word — but when scaled up with billions of parameters and vast data, it becomes the foundation for everything we now call AI writing or text generation. Now, let's see tokenisation.
#2: Tokenisation
Computers don’t understand words directly — they understand numbers. So before a Transformer can read, the text must be tokenised — broken down into smaller units called tokens. Each token is mapped to a unique numerical ID called token ID.
For example:
I am learning NLP.can be broken down into words (or tokens):
I
am
learning
NLP
.
The above tokens can be assigned numbers called token IDs.
Tokens: [40, 939, 7524, 161231, 13]
I ---> 40
am ---> 939
learning ---> 752
NLP ---> 161231
. ---> 13Spaces are also included in some tokens. Typically, one token corresponds to ~4 characters of text. These tokens are what flow through the Transformer!
Tokenisation — The Language Bridge
The process of converting text to tokens and back is called tokenisation. A tokeniser breaks text into smaller pieces (words, subwords, or even bytes), assigns IDs, and sends them into the model.
Text (Input) → Tokeniser → Input Tokens → Model → Output Tokens → Text (Output)
Try it yourself using OpenAI’s Tokeniser demo.
For example: “I am learning NLP.” → [40, 939, 7524, 161231, 13]


#3: Encoder and Decoder
Once our text is tokenised and converted into numerical IDs, the next step is to feed it into the Transformer architecture.
The Transformer is made up of two main parts: an Encoder and a Decoder.
The Encoder takes the input tokens and converts them into contextualised embeddings — numerical representations that capture the meaning and relationships between tokens.
The Decoder takes these embeddings and predicts the next token (or word) in the output sequence.
Think of the Encoder as the part that reads and understands, and the Decoder as the part that writes and generates.
During training, the encoder processes all input tokens at once, while the decoder learns to generate the next token one by one — taking into account everything it has already generated.
The output from the Encoder flows into every layer of the Decoder. The Decoder, in turn, keeps feeding back its own predictions until it reaches a special end-of-sequence token.
Encoder–Decoder Cycle
Input Tokens → Encoder → Contextual Embeddings → Decoder → Output Tokens
The process repeats until the model has generated the full sequence.
So, for our example sentence —
“Humpty Dumpty sat on a wall”
the encoder reads and transforms this sentence into embeddings that represent its meaning. The decoder then starts predicting one token at a time until it reconstructs the full sentence (or continues generating new text).
Each stage helps the model understand not just what the words are, but how they relate to each other.
#4: Attention
The key idea that makes Transformers powerful is the Attention Mechanism — specifically, Self-Attention.
When processing text, the model doesn’t just look at one token at a time. Instead, it looks at all tokens simultaneously and decides how much attention each token should pay to others.
Take our example again:
“Humpty Dumpty sat on a wall”
The word “sat” depends on “Humpty Dumpty” to make sense. Likewise, “wall” connects to “sat”, since that’s where Humpty Dumpty sat.
Through attention, the model learns these relationships automatically. It assigns attention weights — numerical values that tell it which tokens are most relevant to the current one being processed.
This process gives us what are called contextualised embeddings, where each token’s representation depends on all the others around it.
How Attention Works?
In the Attention layer, each token is projected into three different vectors:
Vector | Question it answers |
Query (Q) | “What am I looking for?” |
Key (K) | “What can I offer?” |
Value (V) | “What information do I carry?” |
The model compares the Query of one token with the Keys of all other tokens to determine how relevant they are to each other. These relevance scores are called attention weights.
The output is then a weighted combination of the Value vectors — this gives the model a new, context-aware representation of each token.
Mathematically, this is expressed as:
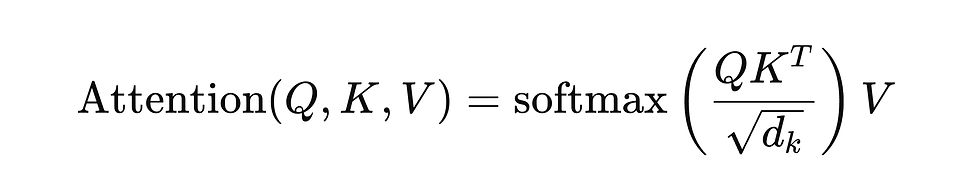
where dk is the dimension of the embedding space, used for normalisation.
That was quite a large and technical post — but no worries. We’ll take it step by step in the coming parts to truly understand the Transformer and even try to build one ourselves.
In the next post, we’ll start with the basics of Self-Attention and Positional Encoding.
References
Sources
Vaswani, A. et al. (2017). Attention Is All You Need. arXiv:1706.03762
Radford, A. et al. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI PDF
Russell, S., & Norvig, P. (2020). Artificial Intelligence: A Modern Approach (3rd ed.). Pearson.











Comments